BROADBENT'S FILTER MODEL
We are constantly bombarded by an endless array of internal and external stimuli, thoughts, and emotions. Given this abundance of available data, it is amazing that we make sense of anything!
In varying degrees of efficiency, we have developed the ability to focus on what is important while blocking out the rest.
What is Selective Attention?
Selective attention is the process of directing our awareness to relevant stimuli while ignoring irrelevant stimuli in the environment.
This is an important process as there is a limit to how much information can be processed at a given time, and selective attention allows us to tune out insignificant details and focus on what is important. This limited capacity for paying attention has been conceptualized as a bottleneck, which restricts the flow of information. The narrower the bottleneck, the lower the rate of flow.

Broadbent's and Treisman's Models of Attention are all bottleneck models because they predict we cannot consciously attend to all of our sensory input at the same time.
Donald Broadbent developed the filter model as an extension of William James’ multi-storage paradigm. Broadbent proposed the notion that a filter acts as a buffer on incoming sensory information to select what information gains conscious awareness. The attended information will pass through the filter, while unattended information will be completely blocked and ignored. The filter acts on stimuli solely on their physical characteristics, such as location, loudness, and pitch.
Cherry: The cocktail party problem
Cherry (1953) found that we use physical differences between the various auditory messages to select the one of interest. These physical differences include differences in the sex of the speaker, in voice intensity, and in the location of the speaker. When Cherry presented two messages in the same voice to both ears at once (thereby removing these physical differences), the participants found it very hard to separate out the two messages purely on the basis of meaning.
Cherry (1953) also carried out studies using a shadowing task, in which one auditory message had to be shadowed (repeated back out aloud) while a second auditory message was presented to the other ear. Very little information seemed to be obtained from the second or non-attended message. Listeners rarely noticed even when that message was spoken in a foreign language or in reversed speech. In contrast, physical changes (e.g., the insertion of a pure tone) were usually detected, and listeners noticed the sex of the speaker and the intensity of sound of unattended messages. The suggestion that unattended auditory information receives very little processing is supported by other evidence. For example, there is very little memory for words on the unattended message even when presented 35 times each (Moray, 1959).
Broadbent (1958) proposed that physical characteristics of messages are used to select one message for further processing and that all others are lost
Information from all of the stimuli presented at any given time enters an unlimited capacity sensory buffer. One of the inputs is then selected on the basis of its physical characteristics for further processing by being allowed to pass through a filter.
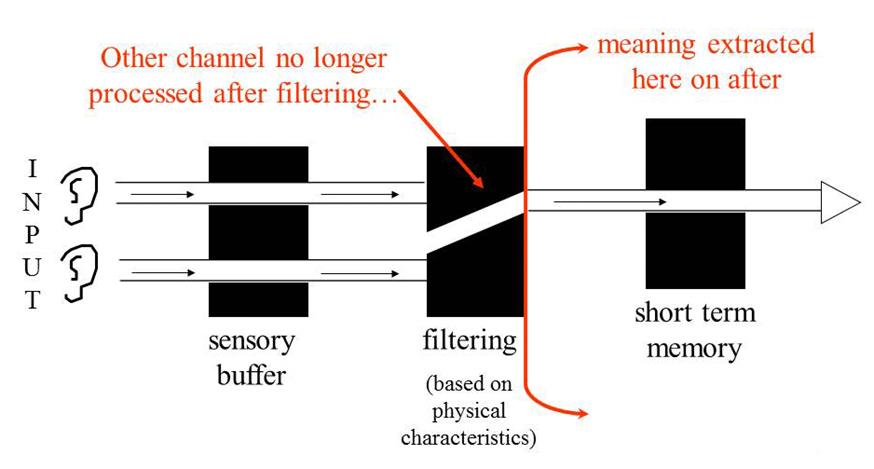
Because we have only a limited capacity to process information, this filter is designed to prevent the information-processing system from becoming overloaded.
The inputs not initially selected by the filter remain briefly in the sensory buffer store, and if they are not processed they decay rapidly. Broadbent assumed that the filter rejected the unattended message at an early stage of processing.
According to Broadbent
the meaning of any of the messages is not taken into account at all by the
filter. All semantic processing is carried out after the filter has
selected the message to pay attention to. So whichever message(s) restricted by
the bottleneck (i.e. not selective) is not understood.
Broadbent wanted to see how people were able to focus their attention (selectively attend), and to do this he deliberately overloaded them with stimuli.
One of the ways Broadbent achieved this was by simultaneously sending one message to a person's right ear and a different message to their left ear. This is called a split span experiment (also known as the dichotic listening task).
Dichotic Listening Task
The dichotic listening tasks involves simultaneously sending one message (a 3-digit number) to a person's right ear and a different message (a different 3-digit number) to their left ear.
Broadbent (1958) discussed findings from what is known as the dichotic listening task. What usually happens is that three digits are presented one after the other to one ear, while at the same time three different digits are presented to the other ear. After the three pairs of digits have been presented, the participants recall them in whatever order they prefer. Recall is typically ear by ear rather than pair by pair. Thus, for example, if 496 were presented to one ear and 852 to the other ear, recall would be 496852 rather than 489562. Note that various kinds of stimuli (e.g., letters, words) can be used with the dichotic listening task.

Participants were asked to listen to both messages at the
same time and repeat what they heard. This is known as a 'dichotic
listening task'.
Broadbent was interested
in how these would be repeated back. Would the participant repeat the digits
back in the order that they were heard (order of presentation), or repeat back
what was heard in one ear followed by the other ear (ear-by-ear).
He actually found that people made fewer mistakes repeating back ear by ear and would usually repeat back this way.
Evaluation of Broadbent's Model
Broadbent's dichotic listening experiments have been criticized because:
1. The early studies all used people who were unfamiliar with shadowing and so found it very difficult and demanding. Eysenck and Keane (1990) claim that the inability of naive participants to shadow successfully is due to their unfamiliarity with the shadowing task rather than an inability of the attentional system.
2. Participants reported after the entire message had been played - it is possible that the unattended message is analyzed thoroughly but participants forget.
3. Analysis of the unattended message might occur below the level of conscious awareness. For example, research by Von Wright et al (1975) indicated analysis of the unattended message in a shadowing task. A word was first presented to participants with a mild electric shock. When the same word was later presented to the unattended channel, participants registered an increase in GSR (indicative of emotional arousal and analysis of the word in the unattended channel).
4. More recent research has indicated the above points are important: e.g. Moray (1959) studied the effects of practice. Naive subjects could only detect 8% of digits appearing in either the shadowed or non-shadowed message, Moray (an experienced 'shadower') detected 67%.
5. Broadbent's theory predicts that hearing your name when you are not paying attention should be impossible because unattended messages are filtered out before you process the meaning - thus the model cannot account for the 'Cocktail Party Phenomenon'.
6. Other researchers have demonstrated the 'cocktail party effect' (Cherry, 1953) under experimental conditions and have discovered occasions when information heard in the unattended ear 'broke through' to interfere with information participants are paying attention to in the other ear.
This implies some analysis of the meaning of stimuli must have occurred prior to the selection of channels. In Broadbent's model, the filter is based solely on sensory analysis of the physical characteristics of the stimuli.
This theory handles Cherry’s basic findings, with unattended messages being rejected by the filter and thus receiving very little processing. It also accounts for performance on Broadbent’s original dichotic listening task, since it is assumed that the filter selects one